Been a while since the last update, I’ve been busy with the new job. Things have been going well!
I went to New York in March for my first week at Datadog, which was a good way to start the job; I met other new joiners, met people on my team, saw a bit of the city. And the view from the office is alright:

Datadog operates at a much larger scale than any company I’ve ever worked at, and that has some upsides and downsides (but mostly upsides). I feel lucky to work with a lot of smart, enthusiastic people.
Last week I was in New York again, for Datadog’s annual DASH conference. I was helping run a booth for my team and it was good to talk to users (and potential users) in person. I got to see a bit more of the city outside of work; the Intrepid Museum was a highlight (an aircraft carrier! a Space Shuttle! a submarine!).
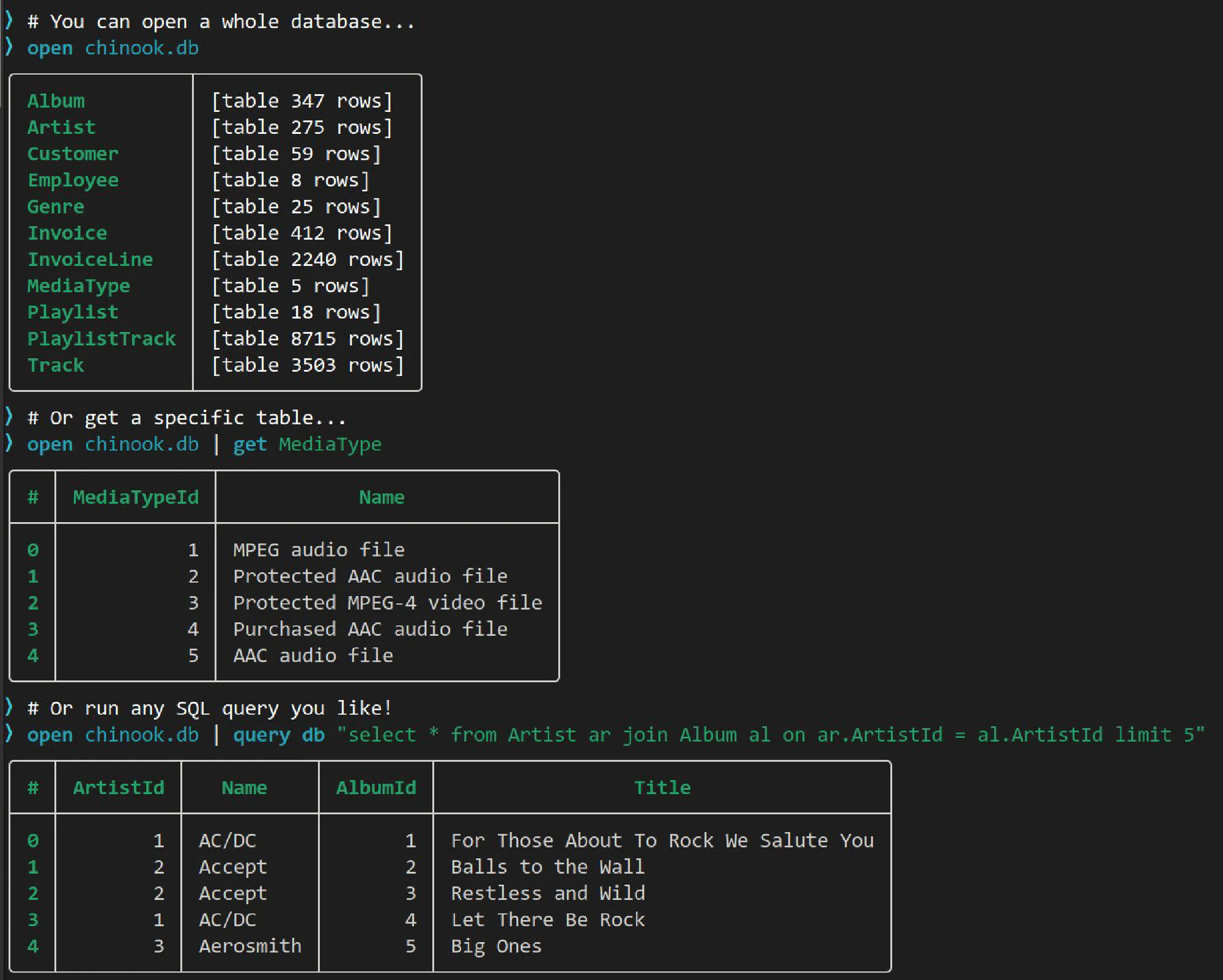
Outside of work, I’ve been spending a little bit of time on Nushell (but not as much as I would like). I’ve been driving some changes to the explore interactive pager (which reminds me, I need to update that documentation). I’m trying to get it to a point where I’m happy with it for version 1.0; I’m not quite there yet but I’ve made a lot of changes under the hood.
Nonfiction I read recently
What Goes Around Comes Around… And Around… (⭐⭐⭐⭐) Michael Stonebraker’s back for another opinionated overview of databases, this time with Andy Pavlo. The whole thing is good but I particularly like their take on vector databases:
They are single-purpose DBMSs with indexes to accelerate nearest-neighbor search. RM DBMSs should soon provide native support for these data structures and search methods using their extendable type system that will render such specialized databases unnecessary
On a related note, I like Simon Willison’s point that maybe you don’t need vectors for RAG:
The more time I spend with this RAG pattern (ed: one using full-text search) the more I like it. It’s considerably easier to reason about than RAG using vector search based on embeddings, and can provide high quality results with a relatively simple implementation.
Fiction I read recently
Lonesome Dove (⭐⭐⭐⭐⭐) This was described to me as “the Western novel to read if you don’t normally read Westerns” and yeah, it was great.
Glorious Exploits (⭐⭐⭐⭐) Funny + touching story about 2 unemployed potters in 412 BC who decide to put on a play with imprisoned Athenian soldiers as the cast.
Microserfs (⭐⭐⭐⭐) Strange that I hadn’t read this before, but Douglas Coupland has a not-entirely-positive reputation in his hometown. He’s kinda known as the guy who got too many undeserved public art commissions around here. Anyway! It was a really fun read and it felt like it could have been written yesterday (surprising for a book about the tech industry written nearly 30 years ago).
A bunch of Horatio Hornblower and Richard Bolitho books (⭐⭐⭐) I was looking for something along the same lines as the excellent Aubrey-Maturin series. These weren’t quite it. Hornblower isn’t very fun as a protagonist and Bolitho is a boring one, I couldn’t make it very far into either series.
 . But until it settles down a bit, expect some growing pains.
. But until it settles down a bit, expect some growing pains.


